
NNUE Explained: The Hybrid Revolution
What you’ll learn: How NNUE combines neural networks with traditional search. Technical deep-dive optional. Reading time: 8 minutes
When DeepMind’s AlphaZero defeated Stockfish in 2017, the message seemed clear: neural networks would replace traditional chess engines. The future was pure machine learning—vast networks trained through self-play, no hand-coded rules, no brute-force search.
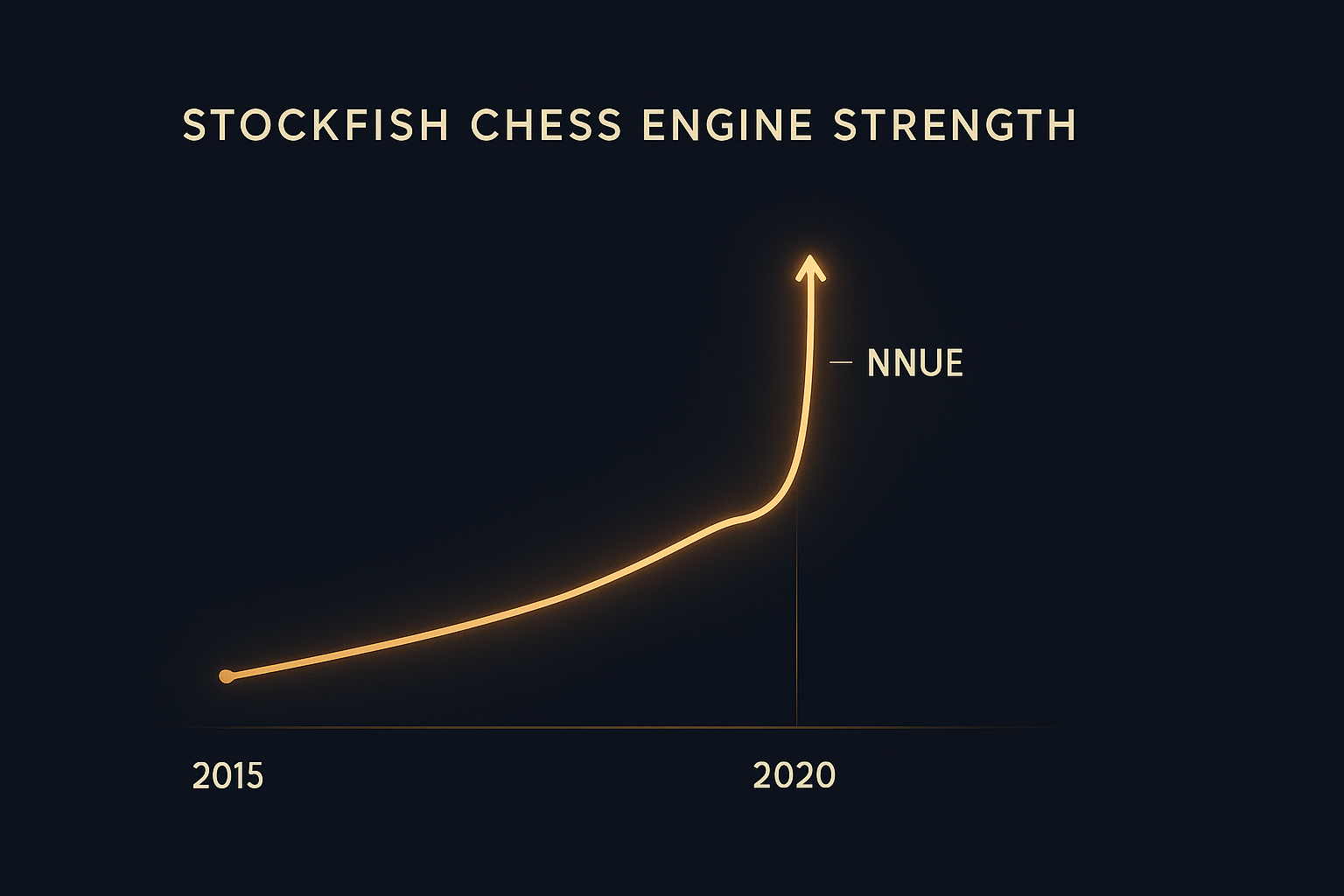
Three years later, Stockfish integrated NNUE and became stronger than ever. Neural networks didn’t replace traditional search. They supercharged it.
The short version: NNUE lets Stockfish use neural network smarts while keeping its speed. Result: 100 Elo stronger overnight. You don’t need to understand how it works to benefit—just know that modern Stockfish is dramatically better than pre-2020 versions.
The problem NNUE solves
Pure neural network engines like Leela Chess Zero have a fundamental limitation: they’re slow. Even on a high-end GPU, Lc0 evaluates 50,000-100,000 positions per second. On CPU alone, it’s glacial—a few hundred positions per second.
Traditional engines like Stockfish evaluate millions of positions per second on a CPU. When Stockfish can search 40 ply deep and Lc0 can only manage 20, Stockfish’s tactical precision usually wins.
But neural networks have something traditional engines lack: pattern recognition that captures positional understanding in ways hand-coded rules can’t match.
NNUE combines both: neural network evaluation that runs at traditional engine speeds.
What changed
In August 2020, Stockfish integrated NNUE (Efficiently Updatable Neural Network), a technology originally developed for Shogi engines. The result was immediate and dramatic.
NNUE replaces the old hand-crafted evaluation function—the part of Stockfish that looked at material, pawn structure, king safety, and dozens of other factors—with a small, fast neural network. The search algorithm stays the same: alpha-beta with all its pruning and extensions.
Stockfish with NNUE evaluates roughly 30 million positions per second on modern hardware. That’s 300-600x faster than Lc0, while still using neural network evaluation.
The results
| Version | Approximate Elo | Notes |
|---|---|---|
| Stockfish 11 | ~3450 | Last version without NNUE |
| Stockfish 12 | ~3550 | First NNUE version |
| Stockfish 14 | ~3600 | Refined NNUE training |
| Stockfish 17 | ~3650+ | Current |
The 100+ Elo jump from SF11 to SF12 was unprecedented. Typical year-over-year gains were 20-30 Elo. NNUE delivered four years of progress instantly.
Since then, improvements have continued. The network architecture has been refined. Training data has expanded. Each version is stronger than the last.
Why it matters for you
Speed: NNUE-Stockfish runs fast on any CPU. No GPU required.
Depth: It can search 40+ ply in complex positions. Tactical accuracy matters.
Accessibility: The same hardware that runs your browser runs Stockfish at full strength.
Predictability: The search-based approach gives consistent, reliable results.
For practical use—game analysis, opening preparation, over-the-board play—NNUE-Stockfish is the best tool available. Pure neural network engines like Lc0 still find creative, strategic ideas that NNUE-Stockfish sometimes misses. But for most purposes, NNUE-Stockfish is faster, stronger, and more practical.
Chessmate gives you access to NNUE-powered Stockfish and other modern engines, so you can benefit from this technology without worrying about the technical details.
The broader lesson
NNUE’s success suggests that the future of AI chess isn’t “neural networks vs. traditional methods.” It’s finding the right combination.
Neural networks excel at pattern recognition and positional evaluation. Traditional search excels at tactical calculation and exhaustive analysis. The best results come from playing to each approach’s strengths.
This hybrid philosophy has influenced other engines too. Komodo Dragon, Berserk, and many modern engines now use NNUE-style evaluation. The technique has become standard.
Optional: How NNUE actually works
This section explains the technical details. Skip it if you just want to use the engine—the information above is all you need.
Input representation
The network takes the board position as input. Rather than a simple 8×8 grid, it uses a sparse representation based on piece-square combinations. For each piece on the board, the network encodes:
- Which piece it is
- Which square it’s on
- The relationship to the king position (king-relative encoding)
This gives the network information about both material and piece placement in a compact form.
The accumulator
Here’s the clever part. The first layer of the network produces an accumulator—a fixed-size vector representing the current position. When a move is made, instead of recalculating the entire accumulator, the engine:
- Subtracts the contribution of the piece on its old square
- Adds the contribution of the piece on its new square
This incremental update is extremely fast—just a few vector additions and subtractions. The expensive part of neural network inference (the first layer) becomes nearly free for move-by-move evaluation.
The rest of the network
The remaining layers are small and fast. They take the accumulator and produce a final evaluation. Because most of the work is in the accumulator (which updates incrementally), the whole evaluation runs quickly.
The network is also quantised—using integers instead of floating-point numbers—which further speeds up computation on CPUs.
Integration with alpha-beta search
NNUE doesn’t replace Stockfish’s search. It replaces the evaluation function.
Traditional Stockfish used hand-crafted evaluation: specific weights for material, pawn structure, king safety, piece mobility, and dozens of other factors. These weights were tuned over years of testing through Fishtest.
NNUE-Stockfish uses the neural network for evaluation instead. The search—alpha-beta with all its pruning and extensions—remains the same. The engine still explores millions of positions per second, still uses transposition tables, still does null move pruning and late move reductions. It just asks the NNUE network “how good is this position?” instead of using the old hand-crafted formula.
This is why the hybrid approach works: NNUE provides positional understanding that’s hard to hand-code, while the traditional search provides tactical depth that pure neural networks can’t match without GPU power.
The integration controversy
When NNUE was proposed for Stockfish in 2020, it was controversial. (For the full story of how this fits into chess engine history, see The Engine Wars.)
Stockfish had spent years refining its hand-crafted evaluation. The team had resisted neural network approaches, viewing them as black boxes that would make the engine harder to understand and improve.
The NNUE patch came from outside the core team. It used a network trained on Stockfish’s own evaluations—essentially distilling the hand-crafted knowledge into a neural format. Some argued this wasn’t “true” neural network chess; others worried it would make future improvements harder.
The debate ended when testing showed NNUE gave Stockfish 80-100 Elo essentially overnight. That’s an enormous gain—years of traditional development compressed into one patch. The results were impossible to ignore.
For Stockfish, NNUE was a turning point. It went from competing with pure neural network engines to clearly dominating them—while remaining free, open-source, and accessible to everyone.